

ETL: Die Legacy Welt vs. Cloud – Was war (zu) teuer, komplex und wenig flexibel
In vielen Unternehmen sind klassische On-Premises-ETL-Prozesse teuer, unflexibel und wartungsintensiv. Monolithische Tools, hohe Lizenzkosten und langsame Bereitstellungen bremsen Innovation und Effizienz. In diesem Beitrag zeigen wir, wie Sie mit Cloud-basierten ETL-Architekturen Kosten senken, Datensilos aufbrechen und Ihre Datenpipelines skalierbar und wartbar gestalten.
On-Premise vs. Cloud
Die Herausforderungen der Legacy-ETL-Welt
Unternehmensweite On-Premises ETL-Prozesse sind häufig durch limitierenden und kostenintensive Eigenschaften geprägt.

Monolithische Tools
wie Informatica PowerCenter, Oracle Data Integrator oder Talend.
Hohe Lizenzkosten
für DBMS, ETL-Engines und Reporting Tools.
Langsame Bereitstellung
neuer Umgebungen durch hohen initialen Aufwand.
Silos statt Integration
da jede Fachabteilung eigene Lösungen nutzt.
Starre Paradigmen
z.B. PL / SQL oder Java-basierte Pipelines.
Manueller Aufwand
beim Skalieren oder Anpassen von ETL-Prozessen.
Vergleich ETL in der Cloud vs. On-Premise
Warum starre Paradigmen an ihre Grenzen stoßen
Neben der reinen Geschwindigkeit der Systeme bietet eine Cloudbasierte ETL Lösung weitere eindeutige Vorteile. Dazu gehören die Lesbarkeit, die Wartbarkeit, die Modularisierung, eine geringere Komplexität sowie automatisierbare Deployments.


Die neue ETL Welt
Die Vorteile von Apache Spark
Apache Spark zeichnet sich besonders durch vier zentrale Vorteile aus.
Skalierbarkeit: Automatische Ressourcenverwaltung in Cloud-Umgebungen
Performance: In-Memory-Analyse und optimierter DAG-Planner (Data Aggregation Graph)
Ökosystem: Nathlose Integration mit Data Lake Architekturen, BI-Tools und ML-Frameworks
Community & Support: Stetige Weiterentwicklung und breite Anwenderbasis
Datensilos aufbrechen
Cloud-native Architektur von ETL-Lösungen
Fachabteilungen setzen häufig eigene ETL- und Data-Warehouse-Lösungen auf – ein Kostentreiber und Hindernis für unternehmensweite Analysen.
Wir beleuchten die Ursachen, zeigen eine Lösung auf, erläutern das Vorgehen und legen den Nutzen dar.
Furcht vor Datenzugriff durch andere Abteilungen sowie langsame Bereitstellung zusätzlicher Kapazitäten in bestehenden Umgebungen.
Ein zentrales Data Governance Modell, das Zugriffskontrollen und Rollen definiert. Außerdem
(Teil-) automatisiertes Onboarding in zentrale Cloud Lösung inkl. Werkzeuge, Storage und Compute-Power, idealerweise in eigenem Workspace (Beispiel: Databricks Workspaces).
Fachbereiche exportieren Daten in einen gemeinsamen Cloud-Storage (z. B. AWS S3, Azure Data Lake Storage) und definieren sog. „Entitlements“ für User, um den Zugriff auf Daten zu schützen.
Außerdem Aufbau eines automatisierten und auditierten Freigabeprozesses.
Schnelles Onboarding neuer Fachbereiche und IT-Abteilungen
Einheitliche Werkzeuge und Standards
Zentrales Monitoring und Operations
Einheitliche Datenquelle für Reporting und ML
Reduzierte Hardware- und Lizenzkosten
Schnellerer Datenaustausch, Transparenz und bessere Kollaborationsmöglichkeiten
Moderne Schnittstellen (REST-APIs) zu Datensets innerhalb des Data Lake
Stefan Klodt - Head of Cloud Technology
"Wenn man ehrlich ist, haben On-Premise-Monolithen für ETL-Prozesse keine Zukunft."

Hoher Aufwand & Kosten
Langsame Bereitstellung und Patching
Der Aufbau neuer On-Premises-Umgebungen ist aufwendig:
- Hardware-Beschaffung und Installation im Rechenzentrum
- Software-Installation und Konfiguration
- Einspielen von Patches und Lizenzschlüsseln
- Test und Abnahme durch Fachabteilung
Solche Projekte können Wochen bis Monate dauern und blockieren Ressourcen für Innovation.
Zudem sind sie ein immenser Kostentreiber der IT.
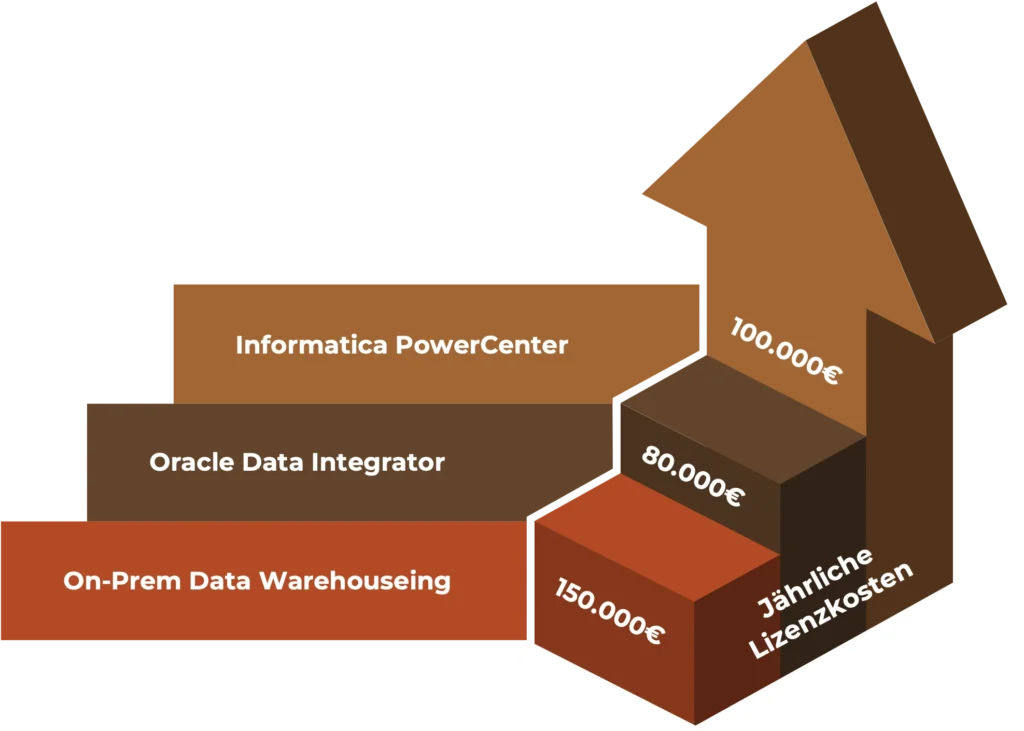
Annahmen für Lizenzkosten starrer On-Premise-Monolithen
Skalierbarkeit
Warum Cloud-ETL klar im Vorteil ist
Automatische Elastizität: Cloud-Dienste wie AWS Glue, Azure Managed Databricks oder Azure Data Factory passen Ressourcen on-the-fly an
Bedarfsorientierte Kosten: Nur für tatsächlich genutzte Rechenzeit bezahlen
Schnelle Test- und Dev-Environments: Mit Infrastructure as Code in Minuten provisionierbar
Bewährte Use Cases: Batch-Ende-Monat-Verarbeitung, Ad-hoc-Analysen oder Streaming-Pipelines


Nur schwer zu bewältigen
Herausforderungen von On-Prem
Aufbau und Zurücksetzen von Testumgebungen
Komplexes Patch- und Update-Management mit langen Testzyklen
Disaster Recovery und Backups
Kaum automatisierte CI/CD-Pipelines
Fazit
Mit Cloud-basiertem ETL Ansatz zum Erfolg
Ein moderner, Cloud-basierter ETL-Ansatz bietet klare Vorteile gegenüber klassischen On-Premises-Lösungen: niedrigere Kosten, höhere Flexibilität, bessere Skalierbarkeit und schnellere Time-to-Market. Durch den Einsatz von Spark-basierten Pipelines und einem zentralen Data Governance Modell schaffen Sie eine agile Dateninfrastruktur, die Ihrem Unternehmen langfristig einen Wettbewerbsvorteil sichert.
Sind Sie an weiteren Best Practices und Deep Dives interessiert? Dann folgen Sie unserem Blog und erfahren Sie mehr zum Thema ETL in der Cloud!
Oder kontaktieren Sie uns für eine individuelle Beratung zu Ihrer ETL-Roadmap.

Ihr Cloud-Projekt in sicheren Händen
Cloud Transformation mit Erfolg
Sind Sie bereit, Ihr Cloud Projekt mit der Expertise aus vielseitigsten erfolgreichen Transformations-Projekten anzugehen?
Kontaktieren Sie dazu gerne unser Team von Experten und lassen Sie uns gemeinsam Ihren Weg zu einer erfolgreichen Cloud Strategie starten.