

Serverlose ETL-Architekturen: Mit Azure und Databricks Legacy-Systeme ablösen und Datensilos aufbrechen
Traditionelle ETL-Landschaften sind vielfach in monolithischen Strukturen verankert. Daten werden zentral gesammelt, transformiert und verteilt. Was in kleinen und stabilen Umgebungen lange Zeit funktionierte, skaliert heute nicht mehr. Die Anforderungen an Datenplattformen haben sich dramatisch gewandelt: Fachbereiche wollen eigene Datenprodukte schnell bereitstellen, Datenzugriffe müssen nachvollziehbar und sicher sein, und Innovation darf nicht durch zentrale Bottlenecks gebremst werden.
Dieser Blog richtet sich an Software-Architekten sowie IT-Entscheider, die bestehende Architekturen in Richtung Cloud, Self-Service und Data Mesh weiterentwickeln wollen. Dabei geht es nicht nur um Technologie, sondern vor allem um ein Ziel: Daten dezentral nutzbar machen, ohne Governance und Sicherheit zu kompromittieren.
Moderne Datenplattform
Architektur & Zielbild
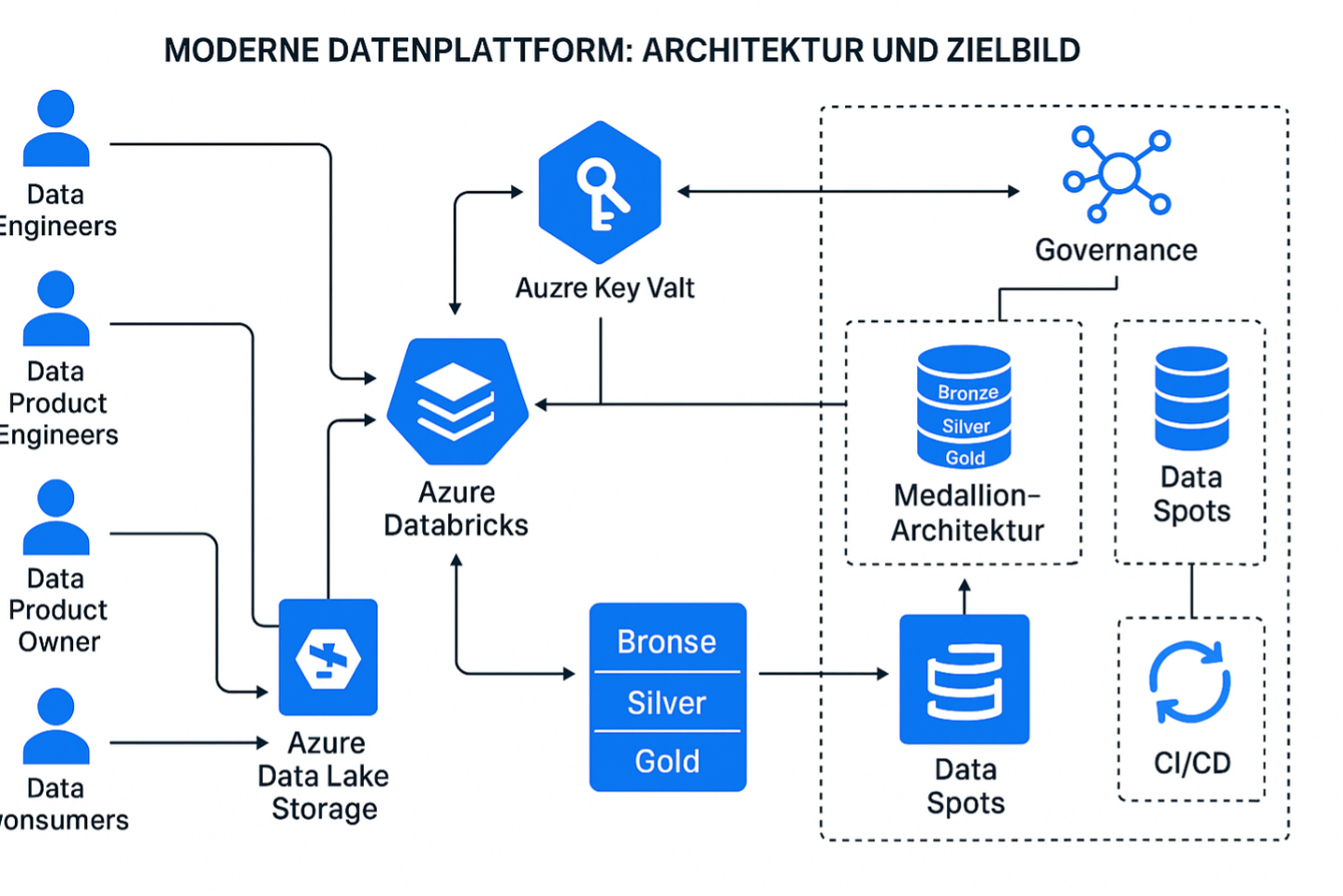
Im Zentrum steht eine serverlose ETL-Architektur, die auf Azure Databricks basiert und Data Mesh Prinzipien umsetzt. Der Grundgedanke: Daten sind Produkte. Sie gehören einer Domäne und werden von dieser verantwortet. Damit wird die Verantwortung stärker in domänen-nahen Teams verankert, während eine zentrale Plattformorganisation gemeinsame Standards und Infrastruktur bereitstellt.
Die Plattform besteht aus sogenannten Data Areas, die Organisationseinheiten wie Fachbereiche oder Geschäftsdomänen abbilden. Innerhalb dieser Data Areas gibt es Data Spots, die konkrete Datenprodukte repräsentieren. Jeder Spot wird von einem dedizierten Data Team betreut, das die komplette Wertschöpfungskette verantwortet: Von der Anbindung der Datenquelle bis zur Bereitstellung von qualifizierten Daten für Analysen, Dashboards oder ML-Modelle.
Die physische Trennung erfolgt über Umgebungen (Development, Test, Production) und eigene Azure-Ressourcengruppen. Jedes Team arbeitet autark in seiner Umgebung, deployt über definierte CI/CD-Pipelines und stellt seine Assets als Versionen über GitHub bereit.
Neue Strukturen erforderlich
Data Governance im Data Mesh
Ein dezentralisiertes Modell erfordert neue Governance-Strukturen. Mit dem Unity Catalog von Databricks steht ein übergreifender Metastore zur Verfügung, der Zugriffsrechte fein granular verwalten kann. Data Contracts sichern die Schnittstellen zwischen Produzenten und Konsumenten. Jeder Zugriff ist nachvollziehbar und revisionssicher.
Es existieren zudem klar definierte Rollen.
Governance ist kein Bremsklotz, sondern Ermöglicher: Standards für Logging, Monitoring, Zugriff, Testing und Deployment werden zentral definiert und lokal umgesetzt.
Bauen technische Pipelines und verbinden Quellsysteme
Übersetzen fachliche Anforderungen in transformationstechnische Logik
Stellen sicher, dass ein Datenprodukt fachlich korrekt und wartbar ist
Konsumieren die Daten in Dashboards, Reports oder Modellen
Stefan Klodt - Manager Digital Innovation Services
„Serverless ETL ist keine rein technische Entscheidung – es ist ein Bekenntnis dazu, Datenverantwortung dorthin zu geben, wo das Fachwissen sitzt: in die Domänen."

Die Medallion-Architektur
Umsetzung in Azure Databricks

Die technische Umsetzung folgt der Medallion Architecture, einem Designmuster, das Datenqualität in Schichten organisiert:
Beispiel: Ein Energiedaten-Use-Case mit Messwerten aus Zählern. In Bronze werden die CSV-Dateien mit Rohdaten geladen. In Silver erfolgt die Typkonvertierung, Prüfung auf Nullwerte und die Anreicherung mit Stammdaten. In Gold werden Monatsmittelwerte und Verbrauchstrends berechnet.
Die Transformationen werden in PySpark umgesetzt. Dabei wird auf wiederverwendbare Module zurückgegriffen, z. B. aus der unternehmenseigenen Bibliothek für Standards wie Typisierung, Logging, Fehlerbehandlung oder Schema Management. Secrets wie Zugangsdaten zu Datenbanken oder APIs werden über Azure Key Vault in Databricks eingebunden und niemals im Code gespeichert.
Infrastruktur und Databricks
CI/CD für serverlose Datenpipelines
Die Trennung von Entwicklung, Test und Produktion ist essenziell. Jede Umgebung hat ihre eigene Azure-Ressourcengruppe, inklusive separater Databricks-Workspaces. Die CI/CD-Pipeline übernimmt den vollautomatischen Übergang eines Datenprodukts zwischen diesen Umgebungen.
- Source Control via GitHub mit Feature-Branches
- Infrastructure-as-Code über Terraform für deklarative Bereitstellung
- Global Parameters für Umgebungsübergreifende Konfiguration
- GitHub Actions orchestrieren Build & Release
- Asset Bundles (YAML-Dateien) beschreiben Jobs, Cluster, Parameter, Permissions
- Deployment via databricks bundle deploy
- Pipelines werden versioniert in GitHub abgelegt
- Build-Prozess wird über Pull Requests und Trigger Events automatisiert
Die Konfiguration erfolgt über zentrale Dateien wie databricks.yaml, bundle.variables.yaml, bundle.targets.yaml und bundle.permissions.yaml. Damit lassen sich mehrere Pipelines modular verwalten und gezielt in spezifische Umgebungen deployen.

Was darüber hinaus wichtig ist
Erweiterbare Konzepte
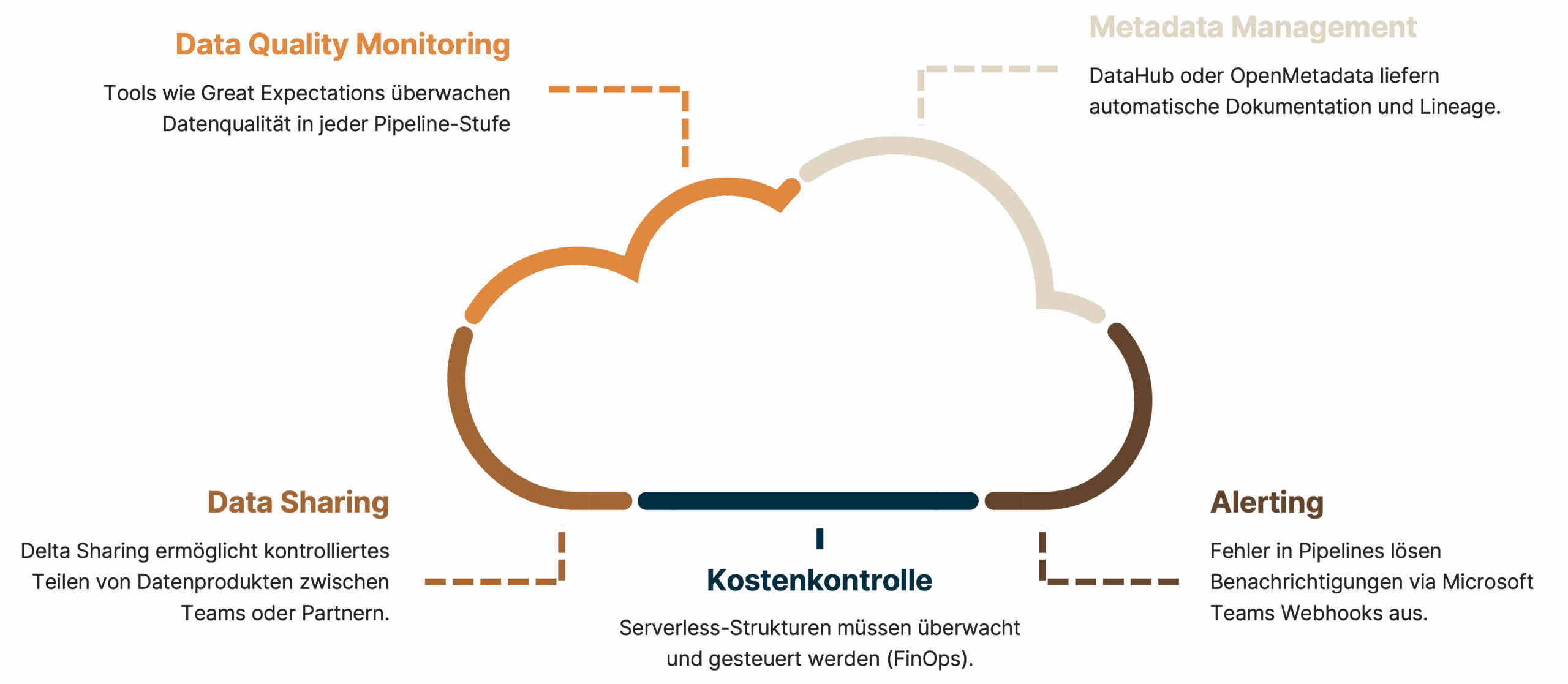
Auch wenn sich dieser Blog auf Architektur, Umsetzung und Deployment konzentriert, spielen weitere Themen eine entscheidende Rolle für den Erfolg:
Die moderne Datenplattform
Fazit & Ausblick
Die Kombination aus Data Mesh, serverloser Infrastruktur und sauberer CI/CD-Integration schafft die Voraussetzungen für eine moderne Datenplattform. Statt monolithischer Data Warehouses entstehen dezentrale, verantwortungsvolle Datenprodukte mit klarer Ownership. Governance wird nicht aufgeweicht, sondern durch Automatisierung verstärkt.
Organisationen, die diesen Weg gehen, schaffen nicht nur technologische Exzellenz, sondern ermöglichen auch datengetriebene Entscheidungen in Echtzeit – skalierbar, sicher und effizient.
Ihr Cloud-Projekt in sicheren Händen
Wie GRAYOAK Sie unterstützt
GRAYOAK unterstützt Unternehmen bei der gesamtheitlichen Cloud Transformation — von der Strategie über die Architektur bis zur Implementierung und zum Rollout. Wir helfen Ihnen, die richtigen Use Cases zu identifizieren, Governance-Rahmen zu etablieren und Workflows skalierbar zu gestalten.